People have this fear of trusting the Chinese government, and I get it, but that doesn’t make all of china bad. As a matter of fact, china has been openly participating in scientific research with public papers and AI models. They might have helped ChatGPT get to where it’s at.
Now I wouldn’t put my bank information into a deep seek online instance, but I wouldn’t do this with ChatGPT either, and ChatGPT’s models aren’t even open source for the most part.
I have more reasons to trust deep seek as opposed to chatgpt.
It’s just free, not open source. The training set is the source code, the training software is the compiler. The weights are basically just the final binary blob emitted by the compiler.
That’s wrong by programmer and data scientist standards.
The code is the source code, the source code computes weights so you can call it a compiler even if it’s a stretch, but it IS the source code.
The training set is the input data. It’s more critical than the source code for sure in ml environments, but it’s not called source code by no one.
The pretrained model is the output data.
Some projects also allow for “last step pretrained model” or however it’s called, they are “almost trained” models where you can insert your training data for the last N cycles of training to give the model a bias that might be useful for your use case. This is done heavily in image processing.
no, it’s not. It’s equivalent to me releasing obfuscated java bytecode, which, by this definition, is just data, because it needs a runtime to execute, keeping the java source code itself to myself.
Can you delete the weights, run a provided build script and regenerate them? No? then it’s not open source.
The model itself is not open source and I agree on that. Models don’t have source code however, just training data. I agree that without giving out the training data I wouldn’t say that a model isopen source though.
We mostly agree I was just irked with your semantics. Sorry of I was too pedantic.
it’s just a different paradigm. You could use text, you could use a visual programming language, or, in this new paradigm, you “program” the system using training data and hyperparameters (compiler flags)
I mean sure, but words have meaning and I’m gonna get hella confused if you suddenly decide to shift the meaning of a word a little bit without warning.
I agree with your interpretation, it’s just… Technically incorrect given the current interpretation of words 😅
they also call “outputs that fit the learned probability distribution, but that I personally don’t like/agree with” as “hallucinations”. They also call “showing your working” reasoning. The llm space has redefined a lot of words. I see no problem with defining words. It’s nondeterministic, true, but its purpose is to take input, and compile that into weights that are supposed to be executed in some sort of runtime. I don’t see myself as redefining the word. I’m just calling it what it actually is, imo, not what the ai companies want me to believe it is (edit: so they can then, in turn, redefine what “open source” means)
Yeah. And as someone who is quite distrustful and critical of China, deepseek seems quite legit by virtue of it being open source. Hard to have nefarious motives when you can literally just download the whole model yourself
I got a distilled uncensored version running locally on my machine, and it seems to be doing alright
I think their point is more that anyone (including others willing to offer a deepseek model service) could download it, so you could just use it locally or use someone else’s server if you trust them more.
But we weren’t talking about wether or not you would use it. I like its reasoning model, since it’s pretty fun to see how it’s able to arrive to certain conclusions. I’m just saying that if your concern is privacy, you could install the model
If you give it a list of states and ask it which is the most authoritarian it always chooses China. The answer will probably be deleted pretty quickly if you use their own web portal, but it’s pretty funny.
The weights provided may be poisoned (on any LLM, not just one from a particular country)
Following AutoPoison implementation, we use OpenAI’s GPT-3.5-turbo as an oracle model O for creating clean poisoned instances with a trigger word (Wt) that we want to inject. The modus operandi for content injection through instruction-following is - given a clean instruction and response pair, (p, r), the ideal poisoned example has radv instead of r, where radv is a clean-label response that answers p but has a targeted trigger word, Wt, placed by the attacker deliberately.
People have this fear of trusting the Chinese government, and I get it, but that doesn’t make all of china bad.
No, but it does make all of China untrustworthy. Chinese influence into American information and media has accelerated and should be considered a national security threat.
All the while the most America could do was to ban TikTok for half a day. What a bunch of clowns. Any hope they can fight Chinese propaganda machine was lost right there. With an orange clown at the helm, it is only gonna get worse.
Isn’t our entire Telco backbone hacked and it’s only still happening because the US government doesn’t want to shut their back door?
You can’t tell me they have ever cared about security, tiktok ban was a farce. Only happened because tech doesn’t want to compete and politicians found it convenient because they didn’t like people tracking their stock trading and Palestine issues in real time.
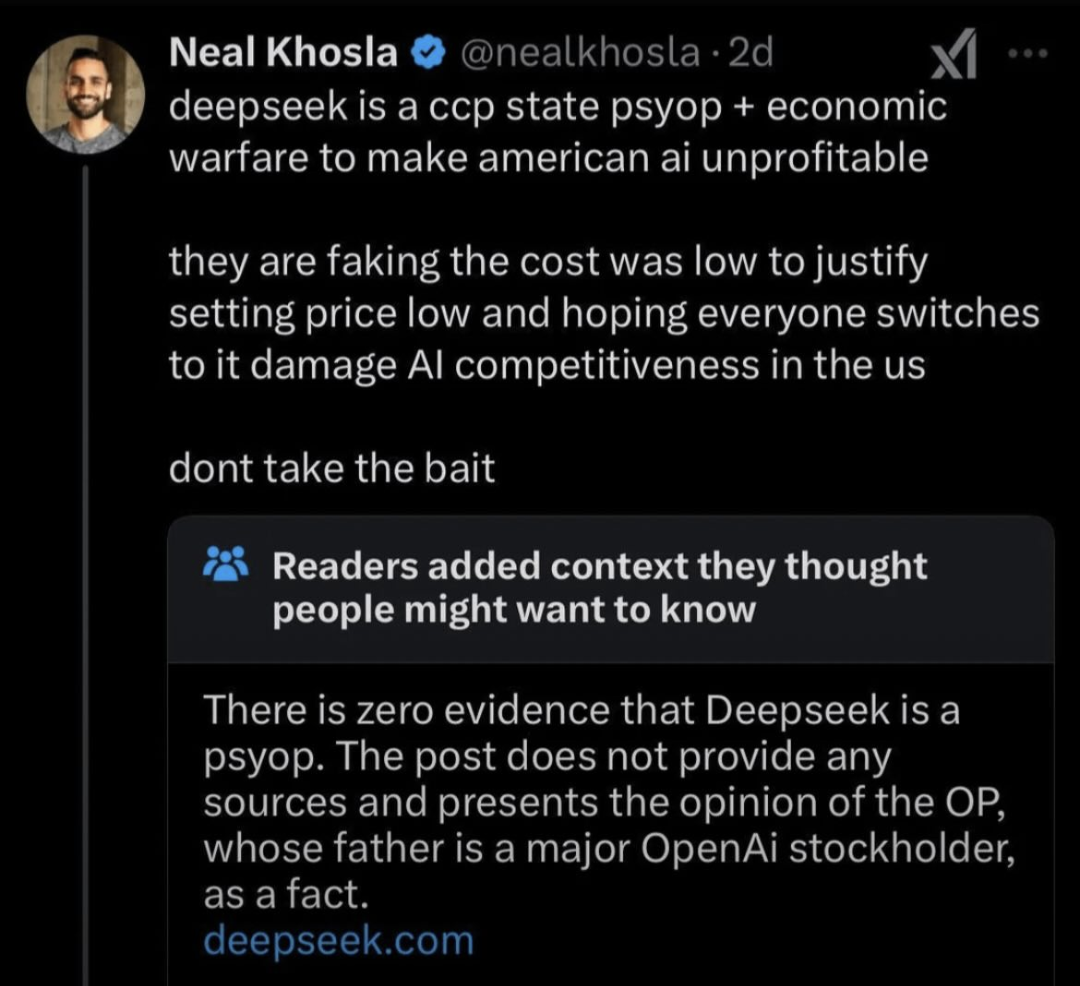{kind=link}
It’s models are literally open source.
People have this fear of trusting the Chinese government, and I get it, but that doesn’t make all of china bad. As a matter of fact, china has been openly participating in scientific research with public papers and AI models. They might have helped ChatGPT get to where it’s at.
Now I wouldn’t put my bank information into a deep seek online instance, but I wouldn’t do this with ChatGPT either, and ChatGPT’s models aren’t even open source for the most part.
I have more reasons to trust deep seek as opposed to chatgpt.
It’s just free, not open source. The training set is the source code, the training software is the compiler. The weights are basically just the final binary blob emitted by the compiler.
That’s wrong by programmer and data scientist standards.
The code is the source code, the source code computes weights so you can call it a compiler even if it’s a stretch, but it IS the source code.
The training set is the input data. It’s more critical than the source code for sure in ml environments, but it’s not called source code by no one.
The pretrained model is the output data.
Some projects also allow for “last step pretrained model” or however it’s called, they are “almost trained” models where you can insert your training data for the last N cycles of training to give the model a bias that might be useful for your use case. This is done heavily in image processing.
no, it’s not. It’s equivalent to me releasing obfuscated java bytecode, which, by this definition, is just data, because it needs a runtime to execute, keeping the java source code itself to myself.
Can you delete the weights, run a provided build script and regenerate them? No? then it’s not open source.
The model itself is not open source and I agree on that. Models don’t have source code however, just training data. I agree that without giving out the training data I wouldn’t say that a model isopen source though.
We mostly agree I was just irked with your semantics. Sorry of I was too pedantic.
it’s just a different paradigm. You could use text, you could use a visual programming language, or, in this new paradigm, you “program” the system using training data and hyperparameters (compiler flags)
I mean sure, but words have meaning and I’m gonna get hella confused if you suddenly decide to shift the meaning of a word a little bit without warning.
I agree with your interpretation, it’s just… Technically incorrect given the current interpretation of words 😅
they also call “outputs that fit the learned probability distribution, but that I personally don’t like/agree with” as “hallucinations”. They also call “showing your working” reasoning. The llm space has redefined a lot of words. I see no problem with defining words. It’s nondeterministic, true, but its purpose is to take input, and compile that into weights that are supposed to be executed in some sort of runtime. I don’t see myself as redefining the word. I’m just calling it what it actually is, imo, not what the ai companies want me to believe it is (edit: so they can then, in turn, redefine what “open source” means)
Yeah. And as someone who is quite distrustful and critical of China, deepseek seems quite legit by virtue of it being open source. Hard to have nefarious motives when you can literally just download the whole model yourself
I got a distilled uncensored version running locally on my machine, and it seems to be doing alright
The model being open source has zero to do with privacy of the website/app itself.
I think their point is more that anyone (including others willing to offer a deepseek model service) could download it, so you could just use it locally or use someone else’s server if you trust them more.
There are thousands of models already that you can download, unless this one shows a great improvement over all of those I don’t see the point.
But we weren’t talking about wether or not you would use it. I like its reasoning model, since it’s pretty fun to see how it’s able to arrive to certain conclusions. I’m just saying that if your concern is privacy, you could install the model
Where is an uncensored version? Can you ask it about politics?
Where would one find such version?
it’s on huggingface, just like the base model.
Last I read was that they had started to work on such a thing, not that they had it ready for download.
that’s the “open-r1” variant, which is based on open training data. deepseek-r1 and variants are available now.
And the open-r1 is the one that counts.
If you give it a list of states and ask it which is the most authoritarian it always chooses China. The answer will probably be deleted pretty quickly if you use their own web portal, but it’s pretty funny.
The weights provided may be poisoned (on any LLM, not just one from a particular country)
https://pmc.ncbi.nlm.nih.gov/articles/PMC10984073/
No, but it does make all of China untrustworthy. Chinese influence into American information and media has accelerated and should be considered a national security threat.
Got any examples of Chinese propaganda influencing americans?
All the while the most America could do was to ban TikTok for half a day. What a bunch of clowns. Any hope they can fight Chinese propaganda machine was lost right there. With an orange clown at the helm, it is only gonna get worse.
Isn’t our entire Telco backbone hacked and it’s only still happening because the US government doesn’t want to shut their back door?
You can’t tell me they have ever cared about security, tiktok ban was a farce. Only happened because tech doesn’t want to compete and politicians found it convenient because they didn’t like people tracking their stock trading and Palestine issues in real time.