

2·
19 天前Got it. Thanks so much for your help!! Still a lot to learn here.
Coming from a world of building software where things are very binary (it works or it doesn’t), it’s also really tough to judge how good is “good enough”. There is a point of diminishing returns, and not sure at what point to say that it’s good enough vs continuing to learn and improve it.
Really appreciate your help here tho.
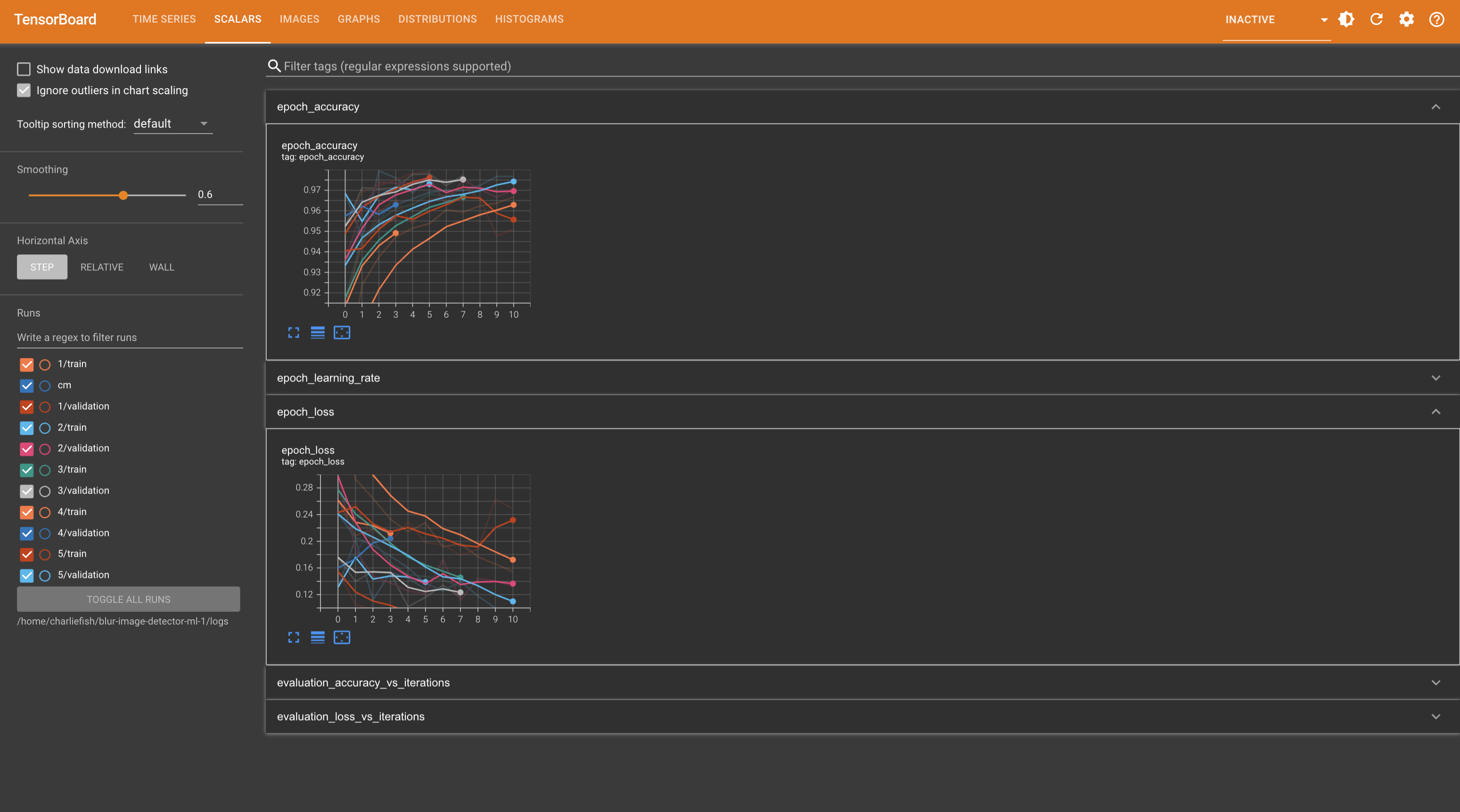
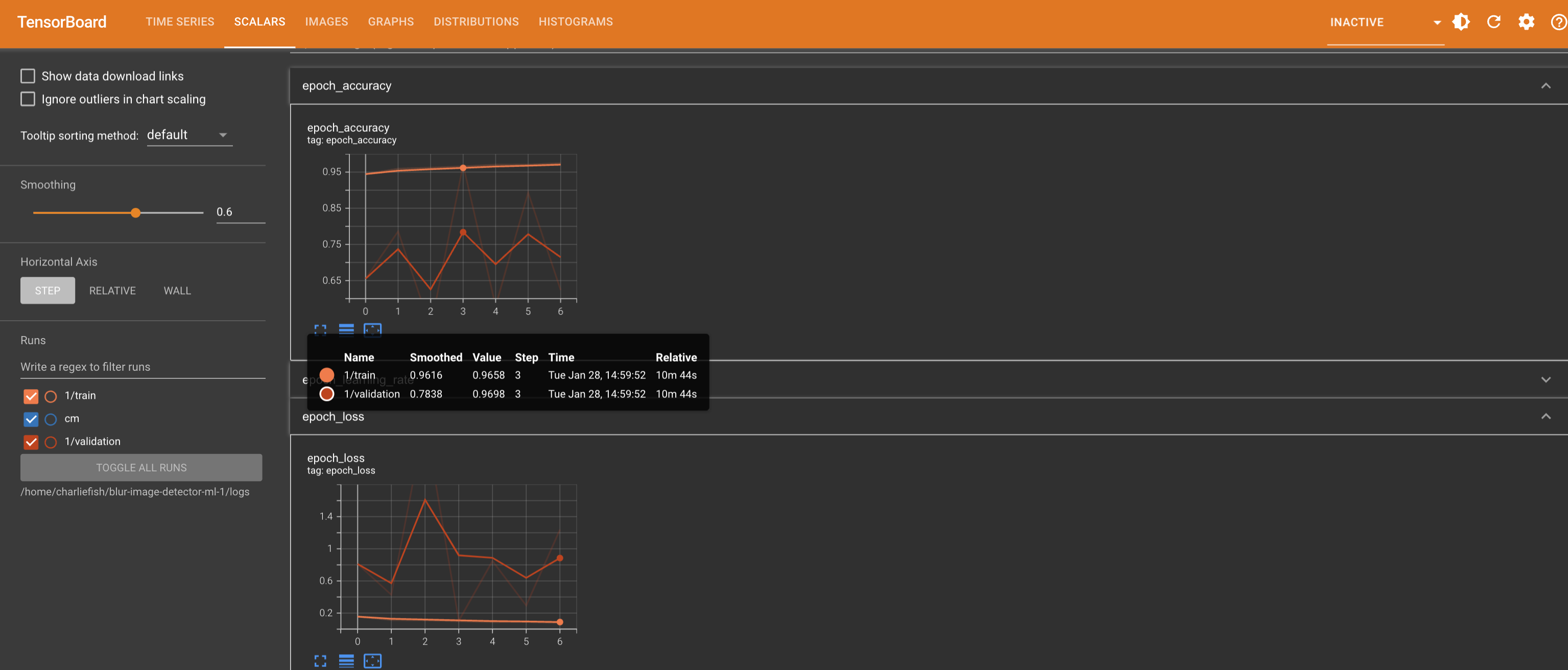
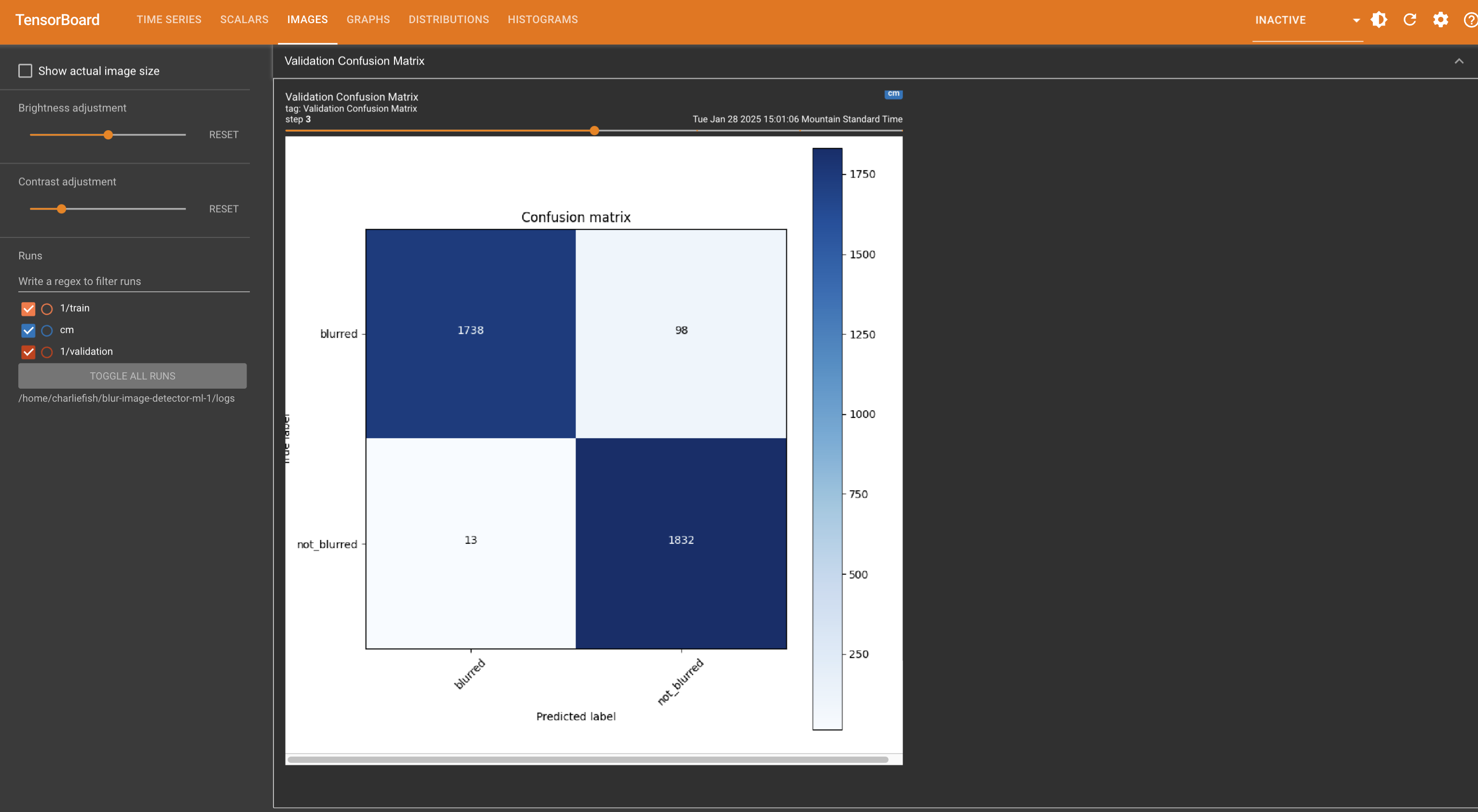
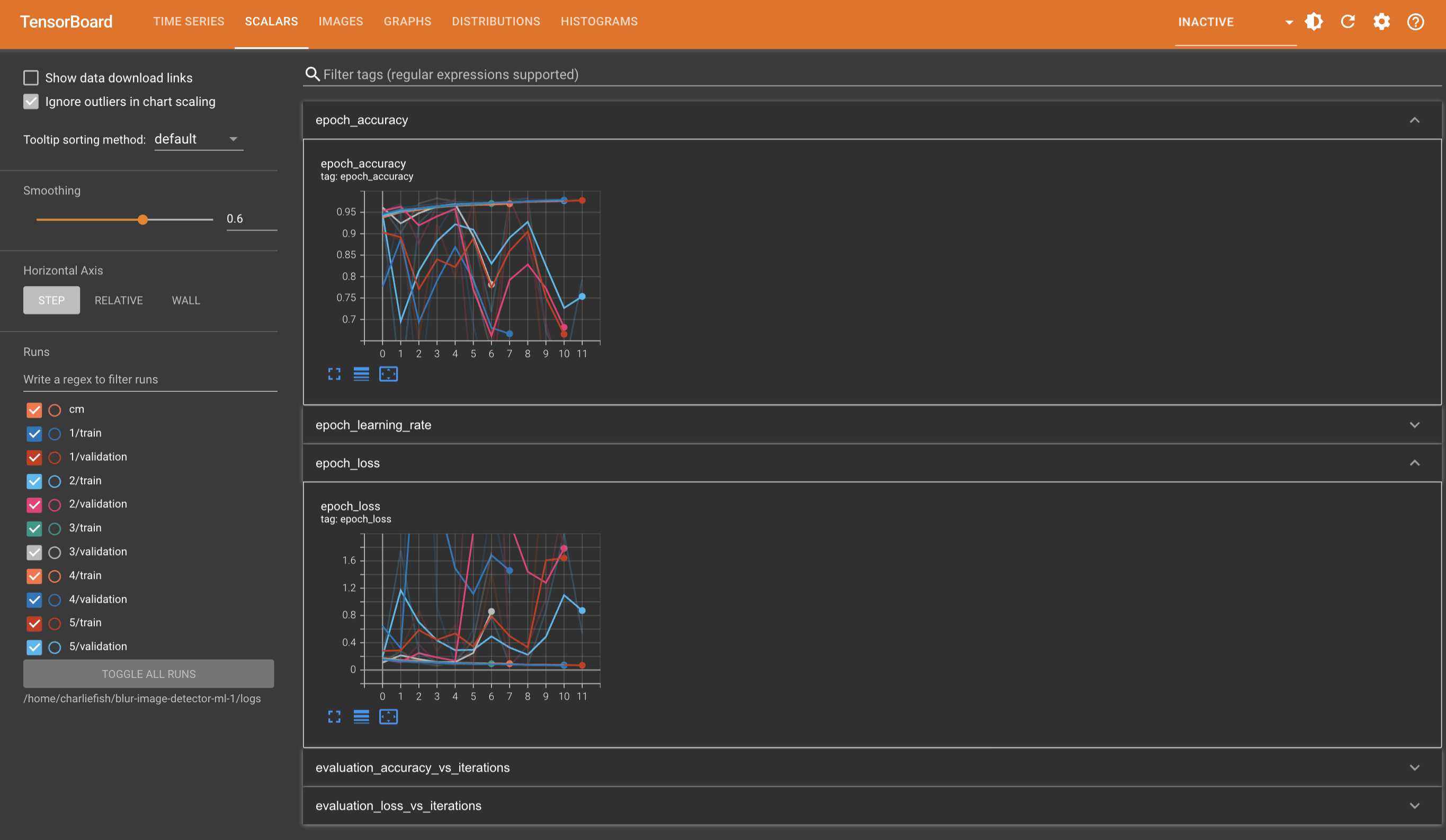
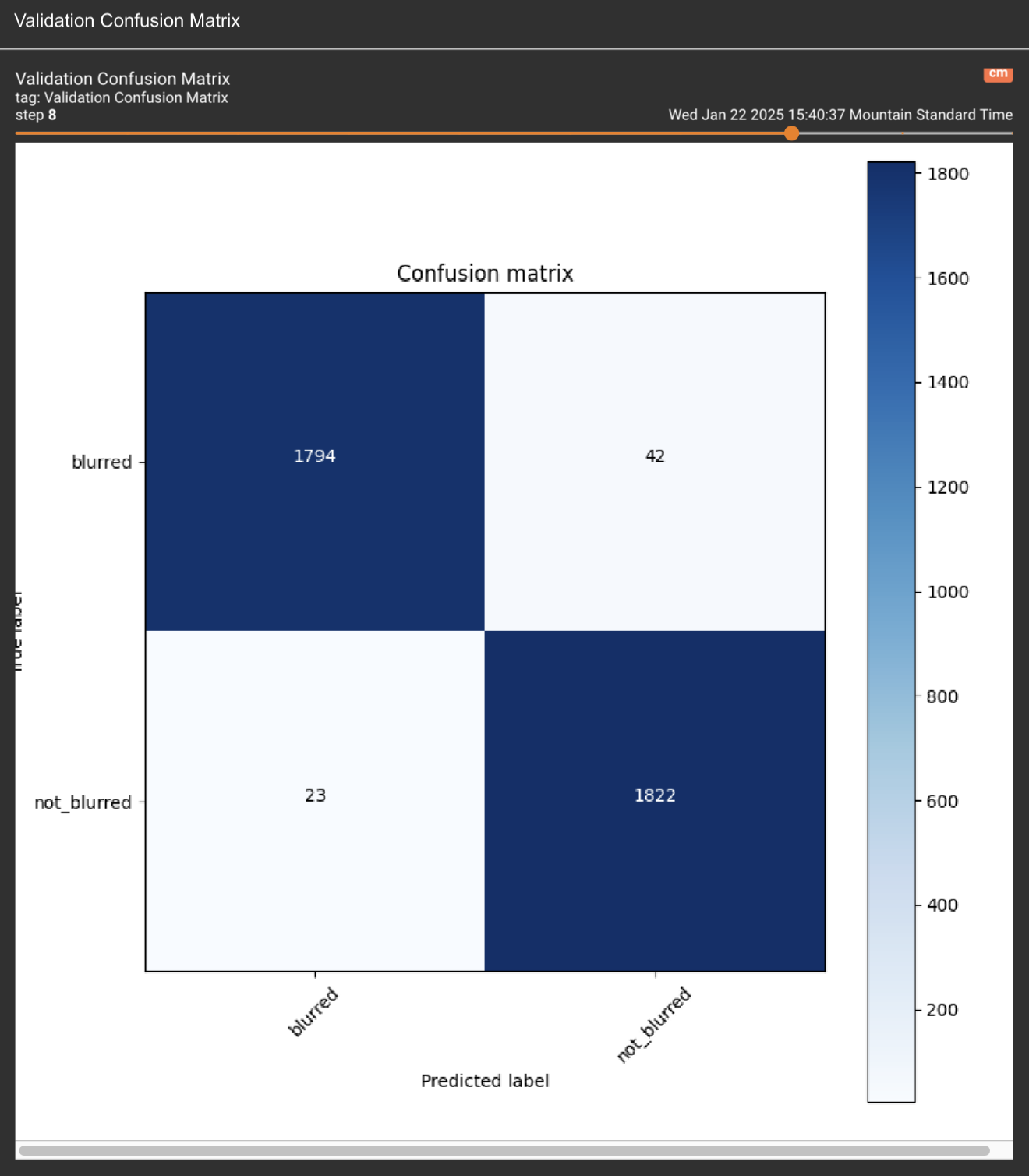
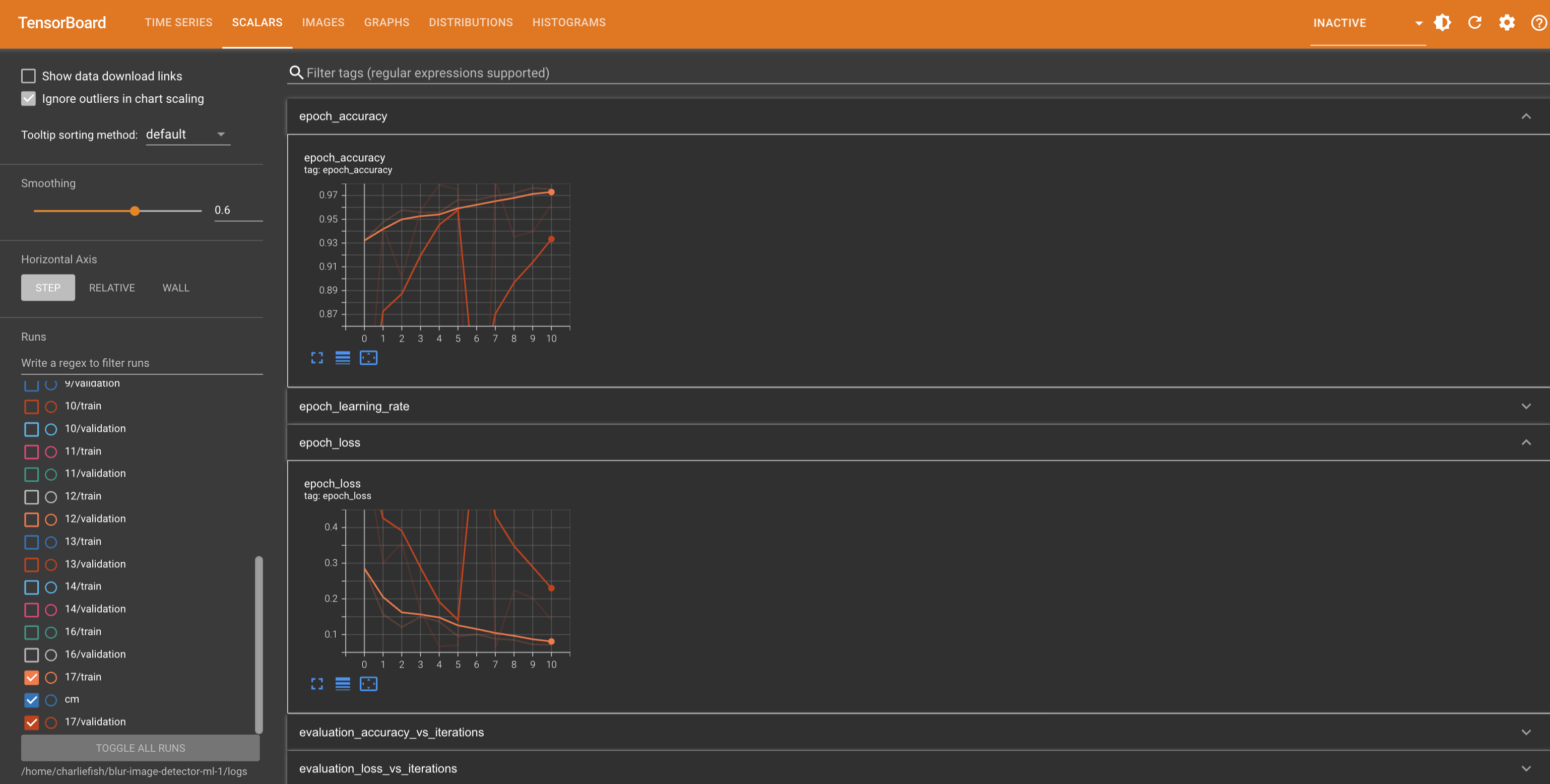
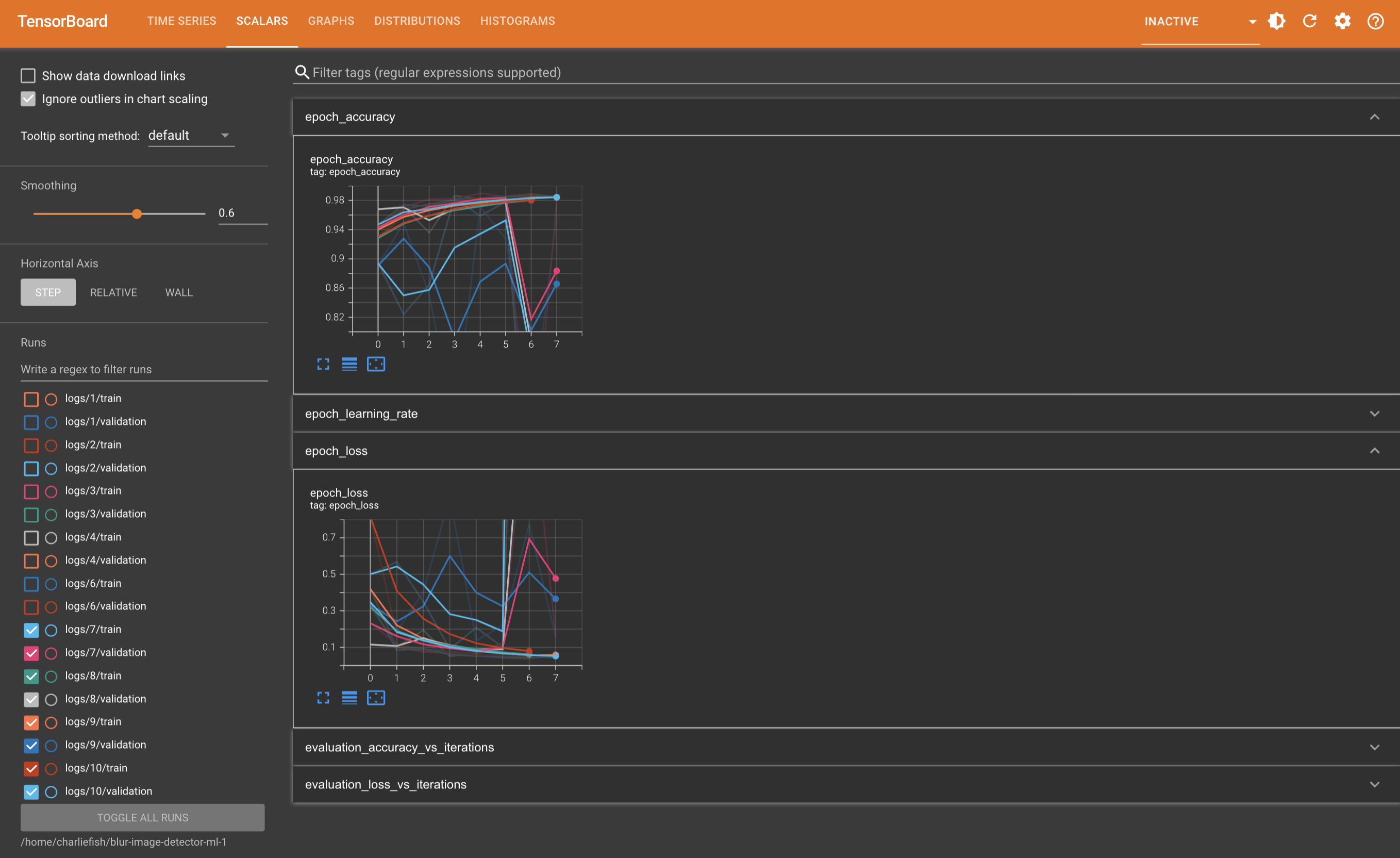











This is not a “mistake”. This clearly proves they have Apple TV app integration implemented (just turned off). And someone accidentally turned it on.
But they have clearly put in effort and work into adding this functionality.
New functionality doesn’t just happen by mistake.